Domain Rules: Invariance and Directional Assertions
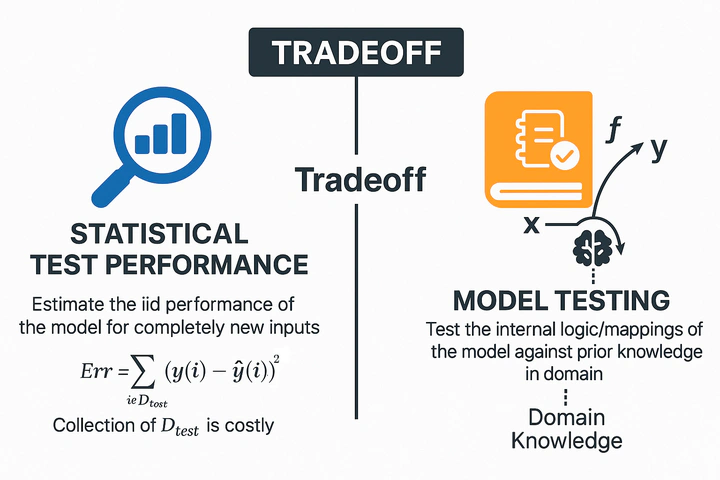 Image credit: ChatGPT
Image credit: ChatGPT
Modern AI models are data-driven pattern hunters.
AI models capture correlations in training sets—but not every correlation reflects reality. Purely data-driven pipelines often leave model logic underspecified [1]. Training on observed examples and testing on similar hold-out data can hide flaws—overfitting to spurious relationships, exploiting shortcuts (X→Y instead of causal Z→Y), or other underspecifications—that only appear in novel scenarios [2].
How do we verify that a model reasons by domain truths—not training quirks? We must go beyond statistics and embed domain knowledge into tests.
Rather than just “Did it predict correctly?”, we ask, “Did it predict for the right reasons?”.
Domain rules become our oracle. By specifying expected behavior under input changes (or invariances), we conduct behavioral tests—akin to software unit tests but driven by domain logic instead of code.
Two core classes of domain-driven tests—invariance and directional expectation—reveal hidden failure modes. Let’s examine each.
Invariances: Ensuring Stability Across Irrelevant Changes
Invariance checks enforce that models ignore irrelevant changes.
- Concept: Some features should not affect predictions.
- Goal: Confirm that these perturbations leave outputs unchanged.
- Failing Invariance: Signals reliance on spurious inputs.
Invariance rules formalize which inputs are irrelevant. Perturb these factors—and the model’s output should stay constant.
- This leverages domain insight to expose spurious dependencies.
- As one study notes, “Generalizing well in supervised learning relies on constraining predictions to be invariant to transformations of the input that are known to be irrelevant to the task”.
Examples of Invariance Rules:
- Image Recognition: Brightness shifts, rotations, resized frames, or slight translations should not alter the predicted class (e.g., a cat remains a cat at dusk).
- Robotics/Autonomous Systems: Small sensor oscillations or calibration shifts should not change perception outputs (e.g., obstacle classification remains stable despite minor exposure or pixel shifts).
- Fraud Detection: Transaction date (non-causal feature) should not affect fraud scores. Perturb dates to reveal if the model exploits time-based shortcuts, risking poor generalization across seasons or years.
Systematic Invariance Verification:
- Identify irrelevant features.
- Generate perturbed inputs altering only those features.
- Validate that model outputs remain consistent (within tolerance).
- Repeat across diverse original samples and perturbations.
Directional Expectations: Enforcing Logical Output Trends
Directional Expectation checks ensure model outputs follow known trends.
- Concept: Predictions should rise or fall predictably with key input shifts.
- Goal: Uncover illogical behaviors that clash with domain wisdom.
- Failing Check: Highlights flawed model logic.
These domain stress tests relies on directional shifts—how outputs should change when inputs vary. Directional expectations assert that nudging key features (while keeping the others constant) only changes predictions in the expected direction, never the opposite.
Domain-Specific Illustrations:
- Credit Risk: Increased income should not raise default probability.
- Healthcare Prognosis: Larger tumors should yield equal or higher mortality risk.
- Autonomous Vehicles: Reduced obstacle distance must increase danger scores.
- Real Estate Pricing: Greater property size should not decrease price estimates.
Compared to Invariances
Directional tests assert a (non-)decreasing or (non-)increasing output trend when inputs shift. Holding other inputs fixed, we vary target features and verify the output’s sign change—akin to checking if ∂f/∂x ≥ 0 (or ≤ 0).
Domain-Aware Verification: Revealing Blind Spots Beyond Accuracy
Invariance and directional tests expose blind spots that accuracy conceals. Even with 95% overall accuracy, critical flaws can lurk in the remaining 5%—often in rare or minority scenarios. Standard test sets miss structured perturbations; domain-aware behavioral tests zoom in on these edge cases.
VerifIA automates tedious manual testing. Instead of handcrafting perturbed inputs and checks, VerifIA uses search-based methods to generate comprehensive test suites at scale. It integrates into MLOps pipelines, running tests on every retrained model—catching logical regressions just as software tests catch code regressions. A failed domain test flags areas for targeted improvement.
Embedding invariance and directional rules into validation boosts confidence in the following ways:
- Limited or Skewed Test Data: Small or homogeneous test sets miss quirks. Domain tests generate targeted examples, revealing failures that static data hides.
- Out-of-Distribution Robustness: Domain rules simulate probable shifts—seasonality, sensor drift—so we anticipate failures before they occur. Enforcing these rules improves cross-domain generalization.
- Safety-Critical Validity: High-stakes systems demand zero catastrophic errors. Domain tests enumerate foreseeable hazards—sensor noise invariance, gust-driven response—and validate against safety laws.
- Building Trust through Transparency: Rule-based tests turn abstract metrics into tangible guarantees. “98% invariance tests passed” is clearer to experts than “95% accuracy.” Each passed rule builds confidence; each failure pinpoints a gap. Aligning models with expected trends fosters stakeholder trust.
Even top-performing models can harbor blind spots. A model that tops leaderboards or sets new benchmarks may still fail for the wrong reasons—flaws hidden by aggregate metrics. Embedding domain knowledge into testing adds a semantic layer:
Does the model reason correctly?
Passing domain-driven tests proves a model is not just accurate but aligned with real-world expectations. It also boosts resilience when facing data outside its narrow training distribution, since we’ve proactively tested those edge cases.
References
- D’Amour et al., Underspecification Presents Challenges for Credibility in Modern Machine Learning, JMLR
- Steinmann et al., Navigating Shortcuts, Spurious Correlations, and Confounders: From Origins via Detection to Mitigation, Arxiv
- Miller et al., AI in Context: Harnessing Domain Knowledge for Smarter Machine Learning, mdpi