Data Bias and Train-Serving Skew: The Hidden Data Traps in AI
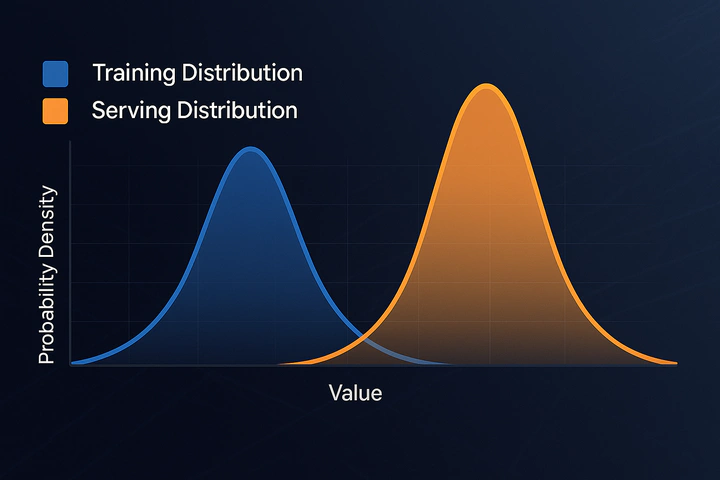 Image credit: ChatGPT
Image credit: ChatGPT
In-Distribution Data Bias
AI models perform only as well as the data they learn from.
If training data is unrepresentative, models produce biased or flawed outputs. One study of 5,000 Stable Diffusion images found amplified gender and racial stereotypes beyond real-world levels. In high-stakes settings—such as police sketch software—these biases can trigger wrongful suspicion or unequal treatment.
Unchecked bias can compromise even the most advanced AI algorithms.
The Skew Problem: Training vs. Serving
In production, data often drifts from what the model saw during training.
Train-serving skew occurs when feature distributions at inference diverge from training. Causes range from evolving user behavior and hardware degradation to upstream pipeline bugs. For example, a pandemic-induced shift in transaction patterns can confuse a fraud detector. An inventory forecaster trained on “clean” data may stumble when sales trends shift—new products, seasons, lockdowns—leading to expired perishables and stockouts of popular items.
Train-serving Skew erodes statistically validated performance in production.
- Ignoring it risks both revenue and reputation.
Double Trouble: Bias Meets Skew
Bias and skew are not isolated risks; they compound one another.
Models trained on historical data inherit past biases, which drifting distributions later amplify. For instance, a model trained on formal text may misinterpret slang or emoji-filled inputs—reinforcing stylistic biases on social media.
Without proper/targeted model verification, these hidden failure modes can destroy trust in AI predictions.
Beyond Static Test Sets
Conventional performance metrics and static test sets fall short.
Traditional testing uses small, randomly sampled test sets that cannot cover all learned behaviors. Domain-aware verification goes further—testing model behavior over broad input regions against predefined, application-specific rules. Examples include:
Invariance Tests — apply input perturbations (e.g., swap demographic attributes) and confirm outputs remain stable.
- Loan Example — swapping racial indicators should not change creditworthiness predictions.
Directional Expectation Tests — apply known shifts and verify predictions move in the correct direction.
- Demand Forecasting Example — rising sales should trigger higher reorder recommendations and stock purchases.
Domain-aware verification uncovers hidden bias and drift early.
Tailored Checks for your Domain Risks
Bias and drift manifest uniquely in each domain; no one-size-fits-all fix exists. You need an intuitive tool that transforms expert insights into automated model checks, guarding against bias and drift before deployment.
VerifIA uses a concise YAML syntax to encode expert rules specifying how your model should—and shouldn’t—behave. It then applies a search-based approach to generate targeted, valid verifications that ensure production model reliability. Additionally, VerifIA’s AI-assisted feature can crawl your domain knowledge and sample from your labeled data, helping you craft comprehensive, precise domain definitions.
References
- MIT Management, When AI Gets It Wrong: Addressing AI Hallucinations and Bias, Basics
- Cem Dilmegani, Bias in AI: Examples and 6 Ways to Fix it in 2025, AIMultiple
- Felipe Almeida and Tiago Magalhães, Dealing with Train-serve Skew in Real-time ML Models: A Short Guide, nubank